Agentic Data Pipelines: The Shift to Autonomous Data Engineering
Data engineering is no longer about building pipelines that follow instructions. It is about building systems that think, adapt, and fix themselves. The traditional model...Read More The post Agentic Data Pipelines: The Shift to Autonomous Data Engineering appeared first on ISHIR | Custom AI Software Development Dallas Fort-Worth Texas.

Data engineering is no longer about building pipelines that follow instructions. It is about building systems that think, adapt, and fix themselves. The traditional model of static workflows, manual monitoring, and reactive debugging is breaking under the pressure of modern data scale and speed.
Agentic data pipelines change that completely. They replace rigid processes with autonomous systems powered by AI agents that can observe, reason, act, and learn in real time. Instead of waiting for engineers to intervene, these pipelines make decisions on their own, handle failures as they happen, and continuously improve from experience.
This shift is not theoretical. It is already redefining how data platforms are built and operated in 2026. In this blog, we break down how agentic pipelines work, what makes them different, and how teams can start adopting them without unnecessary risk.
What Are Agentic Data Pipelines?
Traditional data pipelines follow fixed instructions. Engineers define workflows, schedule jobs, and fix failures manually. Agentic pipelines remove that rigidity. They are AI-driven systems that can reason, plan, act, and learn without constant human input. In 2026, this is no longer experimental. Most new data infrastructure is being created and managed by AI agents, not humans.
The Six Layers of an Agentic Pipeline: How Intelligence Is Built Into Data Systems
1. Intent Layer
The intent layer defines the purpose of the pipeline instead of just the steps. It captures business goals, data consumers, and expectations around freshness, accuracy, and reliability. This allows the system to prioritize decisions dynamically based on outcomes, not instructions. Without intent, the pipeline cannot adapt and simply executes blindly.
2. Observability Layer
The observability layer provides continuous visibility into pipeline health, data quality, and system performance. It tracks metrics like failures, schema drift, anomalies, and SLA breaches in real time. These signals act as the foundation for decision-making. Without strong observability, the system lacks awareness and cannot respond effectively.
3. Reasoning Engine
The reasoning engine is the decision-making core that interprets signals and determines the right course of action. It performs root cause analysis, evaluates possible fixes, and selects the best response based on context. This eliminates generic reactions and replaces them with intelligent, situation-aware decisions. It is what makes the pipeline autonomous instead of reactive.
4. Action Layer
The action layer executes decisions directly within the system by interacting with orchestration tools and infrastructure. It can restart jobs, scale resources, modify queries, or isolate faulty data. This layer ensures that decisions are not just theoretical but actually implemented in production. Speed and reliability of execution define its effectiveness.
5. Memory Layer
The memory layer stores past incidents, decisions, and outcomes to improve future responses. It allows the system to learn from recurring issues and resolve them faster over time. Instead of re-analyzing every problem, the pipeline builds operational intelligence. This continuous learning is what drives long-term efficiency and resilience.
6. Governance Layer
The governance layer enforces policies, controls, and compliance boundaries for all actions. It defines what can be automated, what requires approval, and ensures every decision is logged and traceable. This layer builds trust by balancing autonomy with control. Without governance, the system risks making unchecked changes in production.
AI-Driven Pipeline Automation Loop: From Detection to Self-Healing
Agentic pipelines operate on a continuous loop that enables real-time decision-making and self-healing without human intervention. Each step in the loop plays a distinct role in maintaining and improving the system.
- Observe
Continuously monitors system signals, including logs, metrics, data quality, schema changes, and performance indicators. This step ensures the pipeline has full visibility into both data and infrastructure conditions in real time. - Reason
Analyzes the observed signals to identify root causes of issues. It differentiates between transient errors and deeper systemic problems, then determines the most effective course of action based on context and intent. - Act
Executes the chosen response directly within the system. This could involve retrying jobs, scaling resources, modifying queries, or isolating problematic data to prevent downstream impact. - Remember
Stores the incident, decision, and outcome as part of the system’s memory. This enables faster and more accurate handling of similar issues in the future, improving performance over time.
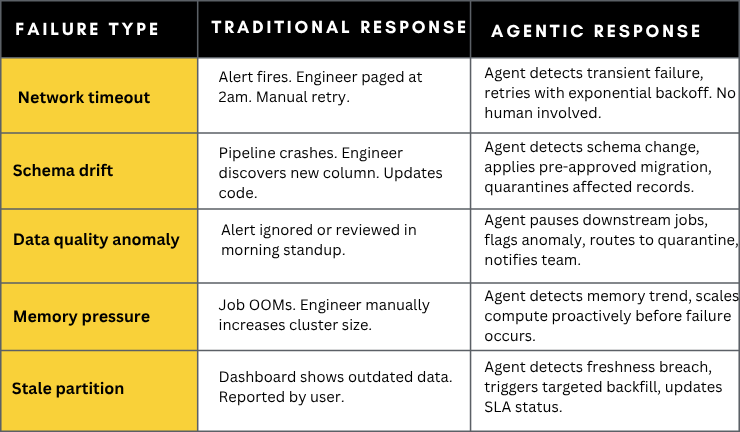
AI-Powered Self-Healing Pipelines for Data Reliability
Self-healing is the immediate payoff. Engineers currently spend a large portion of time identifying and fixing issues. Agentic systems eliminate most of that effort.
Failure scenarios and autonomous responses
Autonomous Data Pipeline Generation: AI-Driven Pipeline Creation from Intent
Autonomous Pipeline Generation
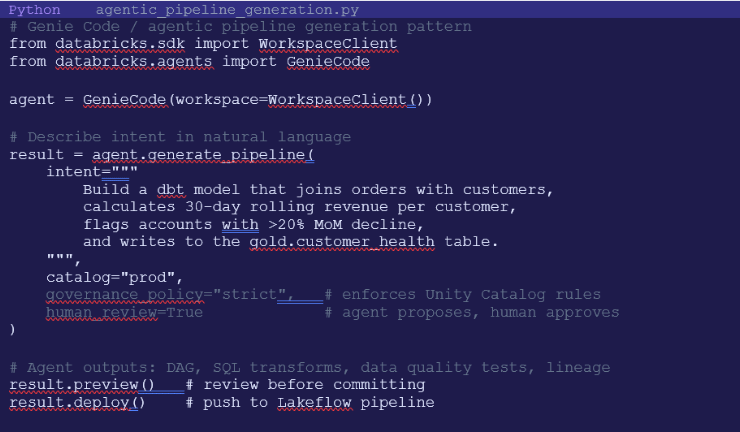
Beyond self-healing, agentic systems can generate entire pipeline components from natural language specifications or by analyzing raw data patterns. Tools like Databricks Genie Code (launched March 2026) and Snowflake Cortex Code represent the leading edge of this capability.
Genie Code reasons through problems, plans multi-step approaches, writes and validates production-grade code, and maintains the result — all while keeping humans in control of the decisions that matter. On real-world data science tasks, it more than doubled the success rate of leading coding agents from 32.1% to 77.1%.
Example: Agent-generated dbt model
Data transformation agents can analyze raw data patterns, suggest and generate dbt models and tests automatically, aligned with organizational best practices. Here is what agent-assisted pipeline generation looks like:
Multi-Agent Data Pipeline Orchestration: Coordinating AI Agents for Scalable, Autonomous Data Engineering
Modern agentic pipelines do not rely on a single AI agent. They operate as coordinated systems of specialized agents, each responsible for a specific function within the data lifecycle. This approach mirrors how high-performing data teams work, but executes at machine speed with continuous coordination and no handoffs.
At the center is the orchestrator agent, which acts as the control layer. It assigns tasks, manages dependencies, resolves conflicts between agents, and maintains a global view of pipeline health. It ensures that all components work in sync and that decisions align with the pipeline’s intent and governance policies.
Supporting it are domain-specific agents:
- Ingestion Agents handle data intake from multiple sources. They monitor schema changes, adjust parsing logic dynamically, and ensure incoming data remains compatible with downstream systems. This reduces breakages caused by upstream changes.
- Data Quality Agents continuously validate data against defined standards. They detect anomalies, enforce data contracts, quarantine bad records, and trigger corrective actions when quality thresholds are violated. This prevents bad data from propagating across the pipeline.
- Transformation Agents generate, optimize, and maintain transformation logic. They build SQL queries, dbt models, and feature engineering workflows while continuously improving performance and efficiency based on usage patterns.
The real complexity lies in coordination. These agents often operate on overlapping responsibilities and shared resources. The orchestration layer must manage dependencies, prioritize tasks, and resolve conflicts in real time. For example, a quality agent may flag an issue while a transformation agent is mid-execution. The orchestrator decides whether to pause, reroute, or continue processing based on impact and policy.
This multi-agent architecture enables parallel execution, faster recovery, and higher system resilience. Instead of a single point of failure, intelligence is distributed across multiple agents that collaborate continuously. The result is a data pipeline that is not just automated, but coordinated, adaptive, and scalable by design.
Governance, Trust & the Human-in-the-Loop
The most common objection to agentic pipelines is: how do you trust a system that modifies production databases without asking permission? The answer is Policy-Based Action Frameworks – a governance layer that defines exactly what agents can and cannot do autonomously.
Policy enforcement levels:
- Notify only – agent identifies issue, logs it, and alerts a human. No autonomous action taken.
- Suggest – agent proposes a specific remediation with reasoning. Human reviews and approves before execution.
- Auto-approve low-risk – agent autonomously executes pre-approved actions (retries, minor schema fixes). Logs all actions.
- Full autonomy with audit – agent acts freely within defined policy boundaries. Every action logged with reasoning traces.
Most organizations start at ‘notify only’ and progressively unlock higher autonomy as trust in the system is established. This graduated approach is critical – it allows teams to validate the agent’s logic in shadow mode before granting write access to production systems.
As agentic operating models mature, data engineers shift from hand-coding transformations to supervising autonomous systems. That means designing guardrails, reviewing agent decisions, and resolving novel edge cases. Explainability becomes core to the model: reasoning traces, auditable logs, and human-in-the-loop checkpoints are required for trust and compliance.
AI-Powered Data Engineering Tools, Roles, and Impact
Agentic Data Platforms
Tools included: Databricks Genie Code, Snowflake Cortex Code
These platforms handle end-to-end pipeline generation, optimization, and deployment. They translate business intent into production-ready workflows using AI. The impact is faster development cycles, reduced manual coding, and higher consistency in pipeline design.
Pipeline Orchestration Tools
Tools included: Apache Airflow, Dagster, Prefect
These tools manage scheduling, dependencies, and execution of data workflows. In agentic systems, they act as execution backbones where AI agents trigger reruns, adjust workflows, and optimize operations in real time. Their role is critical for stability and controlled execution.
Self-Healing and Observability Tools
Tools included: Acceldata ADM, Monte Carlo, OpenTelemetry
These tools provide deep visibility into pipeline health, data quality, and system performance. They enable anomaly detection and support automated remediation through agentic decision-making. The impact is reduced downtime and elimination of manual debugging.
Data Transformation and AI Modeling Tools
Tools included: dbt with AI agents, Spark with LLMs
These tools automate the creation and optimization of data transformations. They generate SQL models, enforce data tests, and improve performance based on usage patterns. This reduces engineering effort while improving data reliability and scalability.
Data Governance and Lineage Tools
Tools included: Unity Catalog, Apache Atlas, OpenLineage
These systems enforce access controls, maintain lineage, and ensure compliance. They define what actions agents can take and provide full auditability of every decision. Their impact is trust, transparency, and safe automation in production environments.
Memory and Context Stores
Tools included: LanceDB, Chroma, Vector databases
These systems store historical context, past incidents, and decision outcomes. They allow AI agents to learn from previous scenarios and improve over time. The result is faster resolution of recurring issues and continuous system optimization.
Agentic Data Pipeline Implementation Roadmap
Step 1: Start with AI-Assisted Pipeline Development
Adopt AI coding tools like GitHub Copilot, Databricks Genie Code, or Snowflake Cortex Code to accelerate pipeline creation. This delivers immediate productivity gains without changing existing architecture. It is the lowest-risk entry point into agentic systems.
Step 2: Implement Automated Data Quality Monitoring
Deploy ML-based data quality and anomaly detection tools to replace static rules. This improves accuracy in detecting issues and significantly reduces alert fatigue. It builds the foundation for intelligent decision-making.
Step 3: Deploy Self-Healing Agents in Shadow Mode
Introduce agentic systems in “suggest only” mode where they recommend fixes but do not execute them. Monitor their decisions over a few weeks to validate accuracy and build trust. This step ensures safe evaluation before automation.
Step 4: Define Governance and Policy Frameworks
Establish clear rules for what actions can be automated and what requires human approval. Start with strict controls and gradually allow low-risk autonomous actions. Governance is critical to ensure safe and compliant operations.
Step 5: Enable the Autonomous Pipeline Loop
Activate the full observe-reason-act-remember loop with controlled autonomy. Allow agents to execute approved actions, learn from outcomes, and continuously improve. Conduct regular audits to ensure decisions remain aligned with business intent and policies.
How ISHIR Helps You Build Agentic Data Pipelines
ISHIR helps organizations transition from traditional data pipelines to agentic, AI-driven systems by combining Agentic AI development with deep data engineering expertise. We design and build intelligent agents, modernize pipeline architectures, and integrate observability, orchestration, and self-healing capabilities to create scalable, autonomous data platforms aligned with business outcomes.
Beyond implementation, ISHIR enables real business impact through advanced data analytics and hands-on Data + AI workshops. We help teams unlock actionable insights, define clear adoption roadmaps, and build internal capability to manage and scale agentic systems with confidence and control.
Struggling with fragile data pipelines, constant failures, and manual fixes slowing your team down?
ISHIR helps you build AI-powered, self-healing data pipelines that automate operations and scale with confidence.
FAQs on Agentic Data Pipelines and AI-Driven Data Engineering
Q. What is an agentic data pipeline and how is it different from traditional pipelines?
An agentic data pipeline is an AI-driven system that can observe, reason, act, and learn without constant human intervention. Unlike traditional pipelines that follow fixed workflows, agentic pipelines adapt dynamically to changes in data, schema, and system conditions. They do not just execute tasks, they make decisions based on context and intent. This shift reduces manual debugging, improves reliability, and enables real-time optimization. It is a move from static automation to intelligent autonomy.
Q. How do AI agents actually improve data pipeline reliability?
AI agents improve reliability by continuously monitoring system health and data quality, then taking corrective action instantly. Instead of waiting for alerts and manual fixes, they identify root causes and resolve issues such as failures, anomalies, or schema changes in real time. They also learn from past incidents, which means recurring problems are handled faster and more accurately. This significantly reduces downtime, data inconsistencies, and operational overhead.
Q. Are agentic data pipelines safe to use in production environments?
Yes, but only when implemented with strong governance frameworks. Most organizations start with limited autonomy where agents suggest actions instead of executing them. Over time, low-risk actions like retries or scaling are automated, while critical changes still require approval. Every action is logged, traceable, and aligned with policy rules. This controlled approach ensures safety, compliance, and trust while gradually increasing automation.
Q. What are the main challenges in adopting agentic pipelines?
The biggest challenges are trust, governance, and system integration. Teams often hesitate to allow AI systems to modify production data without oversight. There is also complexity in integrating AI agents with existing orchestration, monitoring, and data systems. Another challenge is defining clear intent and policies so agents can make correct decisions. Successful adoption requires a phased approach with validation, monitoring, and gradual rollout.
Q. Do agentic pipelines replace data engineers?
No, they change the role of data engineers rather than replacing them. Engineers move from writing and fixing pipelines to designing systems, defining policies, and supervising AI agents. They focus more on architecture, governance, and optimization instead of repetitive operational tasks. This shift increases productivity and allows teams to handle larger, more complex data environments with fewer resources.
Q. What tools are commonly used to build AI-driven data pipelines?
The ecosystem includes agentic platforms like Databricks Genie Code and Snowflake Cortex, orchestration tools like Airflow and Dagster, and observability tools like Monte Carlo and OpenTelemetry. Transformation tools such as dbt combined with AI agents automate modeling and SQL generation. Governance tools ensure compliance, while vector databases store memory for learning. These tools work together to enable intelligent, autonomous pipeline behavior.
Q. How can organizations start implementing agentic data pipelines today?
The best approach is to start small and build progressively. Begin with AI-assisted development to speed up pipeline creation, then implement automated data quality monitoring. Introduce agentic systems in a suggestion mode to validate their decisions before enabling automation. Define governance policies early to control risk. Once trust is established, gradually activate full autonomy with continuous monitoring and audits. This phased strategy ensures safe and effective adoption.
The post Agentic Data Pipelines: The Shift to Autonomous Data Engineering appeared first on ISHIR | Custom AI Software Development Dallas Fort-Worth Texas.
Share
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0